http://argos.vu/devnotes-11-11-16-save-and-reload/
Problem and Solution: The Terrible Inefficiency of FileStream and BinaryReader
File I/O can be a major performance bottleneck for many apps. It’s all too easy to read files in a way that is massively inefficient. Classes like FileStream and BinaryReader make it really easy to write super slowcode. Today’s article explores why this happens and what can be done about it. Read on to learn more!
Say you want to read a 10 megabyte file containing a huge series of unsigned 2-byte values: ushort. How do you read this file? The typical approach would involve a FileStream and a BinaryReader like this:
// Open the file
using (var stream = new FileStream("/path/to/file", FileMode.Open))
{
// Compute how many values the file has
var numValues = stream.Length / sizeof(ushort);
// Allocate an array to hold all those values
var readValues = new ushort[numValues];
// Open a reader to make reading those values easy
using (var reader = new BinaryReader(stream))
{
// Read all the values
for (var i = 0; i < numValues; ++i)
{
readValues[i] = reader.ReadUInt16();
}
}
}
On my test system (described later), this takes about 272 milliseconds! That’s definitely long enough that you’ll need to spread the load out over multiple frames of the game in order to keep a smooth frame rate. Maybe you’ll use another thread to handle the task. Regardless, your code is about to get a lot more complex, error-prone, and difficult to manage. Not to mention the user is going to have to wait longer for the file to get loaded.
But what if we could load the file faster? We know it’s important to minimize the number of read() calls made to the OS and FileStream does that for us. It has an internal buffer that defaults to a perfectly-reasonable 4 kilobytes in size. So when you read the first two bytes of the file it actually reads 4 kilobytes. The second read just takes two bytes out of the buffer and doesn’t make any read() calls to the OS. Great!
With this in mind we can plot the performance of different size reads from FileStream using its Readfunction:
var numBytesRead = myFileStream.Read(myBuffer, offsetIntoMyBuffer, numBytesToRead); |
Here’s what happens when I run that test on the same test system as above:
| Read Size | Time |
|---|---|
| 2 | 227 |
| 4 | 118 |
| 8 | 58 |
| 16 | 31 |
| 32 | 17 |
| 64 | 10 |
| 128 | 6 |
| 256 | 4 |
| 512 | 3 |
| 1024 | 3 |
| 2048 | 3 |
| 4096 | 3 |
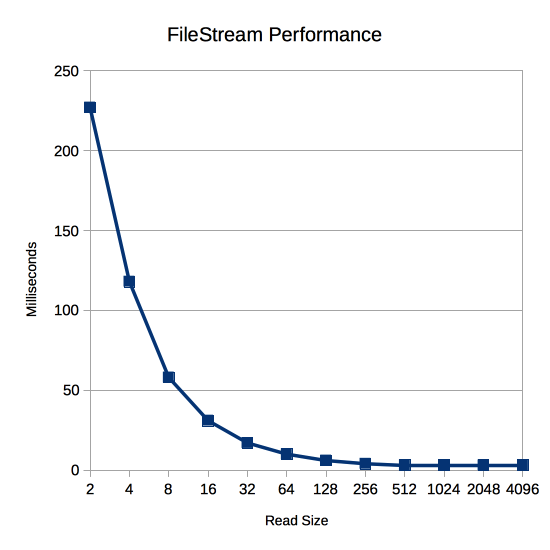
The read size makes a huge difference! Just reading 4096 bytes at a time instead of 2 bytes at a time is 75x faster! But why is this the case? Isn’t FileStream just copying from its internal buffer? Isn’t that way faster than reading from the file system?
The answer lies in the CPU performance of FileStream, not the disk I/O performance. To find out why it’s so slow, let’s decompile the mscorlib.dll that comes with Unity 5.4’s version of Mono and see how FileStream is implemented. First, here’s the Read we call from our app:
public override int Read([In] [Out] byte[] array, int offset, int count)
{
if (this.handle == MonoIO.InvalidHandle)
{
throw new ObjectDisposedException("Stream has been closed");
}
if (array == null)
{
throw new ArgumentNullException("array");
}
if (!this.CanRead)
{
throw new NotSupportedException("Stream does not support reading");
}
int num = array.Length;
if (offset < 0)
{
throw new ArgumentOutOfRangeException("offset", "< 0");
}
if (count < 0)
{
throw new ArgumentOutOfRangeException("count", "< 0");
}
if (offset > num)
{
throw new ArgumentException("destination offset is beyond array size");
}
if (offset > num - count)
{
throw new ArgumentException("Reading would overrun buffer");
}
if (this.async)
{
IAsyncResult asyncResult = this.BeginRead(array, offset, count, null, null);
return this.EndRead(asyncResult);
}
return this.ReadInternal(array, offset, count);
}
Whoa! 8 if statements right off the bat! Those can be quite slow because the CPU doesn’t know which code—the if or the else—is going to get executed, so it breaks its ability to predict and slows the code down. Notice that they’re mostly sanity checks, too. Is the stream open? Did you pass a null array? Can you read from this stream? Are your offset and count non-negative? The odds are extremely high that you’re not making any of these mistakes, but you’re going to pay for them 5,242,880 times over the course of a 10 megabyte file!
Next let’s look at the ReadInternal call at the end of Read:
private int ReadInternal(byte[] dest, int offset, int count)
{
int num = 0;
int num2 = this.ReadSegment(dest, offset, count);
num += num2;
count -= num2;
if (count == 0)
{
return num;
}
if (count > this.buf_size)
{
this.FlushBuffer();
num2 = this.ReadData(this.handle, dest, offset + num, count);
this.buf_start += (long)num2;
}
else
{
this.RefillBuffer();
num2 = this.ReadSegment(dest, offset + num, count);
}
return num + num2;
}
Here we’ve got one or two more if statements for a total of 9-10 so far across three function calls (FileStream.Read, Stream.Count, FileStream.ReadInternal). Right away this function calls into another function: ReadSegment
private int ReadSegment(byte[] dest, int dest_offset, int count)
{
if (count > this.buf_length - this.buf_offset)
{
count = this.buf_length - this.buf_offset;
}
if (count > 0)
{
Buffer.BlockCopy(this.buf, this.buf_offset, dest, dest_offset, count);
this.buf_offset += count;
}
return count;
}
Two more if statements for a total of 11-12 and 4 function calls. Here’s Buffer.BlockCopy:
public static void BlockCopy(Array src, int srcOffset, Array dst, int dstOffset, int count)
{
if (src == null)
{
throw new ArgumentNullException("src");
}
if (dst == null)
{
throw new ArgumentNullException("dst");
}
if (srcOffset < 0)
{
throw new ArgumentOutOfRangeException("srcOffset", Locale.GetText("Non-negative number required."));
}
if (dstOffset < 0)
{
throw new ArgumentOutOfRangeException("dstOffset", Locale.GetText("Non-negative number required."));
}
if (count < 0)
{
throw new ArgumentOutOfRangeException("count", Locale.GetText("Non-negative number required."));
}
if (!Buffer.BlockCopyInternal(src, srcOffset, dst, dstOffset, count) && (srcOffset > Buffer.ByteLength(src) - count || dstOffset > Buffer.ByteLength(dst) - count))
{
throw new ArgumentException(Locale.GetText("Offset and length were out of bounds for the array or count is greater than the number of elements from index to the end of the source collection."));
}
}
if statements and we’re up to 17-18 and 5 function calls. Many of these checks are redundant with checks that have already been performed. At the end this calls Buffer.BlockCopyInternal and Buffer.ByteLength:[MethodImpl(MethodImplOptions.InternalCall)]
internal static extern bool BlockCopyInternal(Array src, int src_offset, Array dest, int dest_offset, int count);
public static int ByteLength(Array array)
{
if (array == null)
{
throw new ArgumentNullException("array");
}
int num = Buffer.ByteLengthInternal(array);
if (num < 0)
{
throw new ArgumentException(Locale.GetText("Object must be an array of primitives."));
}
return num;
}
[MethodImpl(MethodImplOptions.InternalCall)]
private static extern int ByteLengthInternal(Array array);
That’s three more function calls for a total of 8, two of which are in native C code. ByteLength does some more redundant if checking to bring the count up to 19-20.
After that in ReadInternal we’re just dealing with the cases where data needs to actually be read from the file system. If we’re reading 2 bytes at a time with a 4096 byte buffer, that’s an extreme minority of calls. Feel free to look through the code with a decompiler if you want, but I’ll skip it for the purposes of this article.
Now that we’ve seen that a call to FileStream.Read results in 8 function calls and 19-20 if statements just to read two bytes, let’s look and see what additional overhead is incurred by using BinaryReader. Here are the functions involved in calling its ReadUInt16:
[CLSCompliant(false)]
public virtual ushort ReadUInt16()
{
this.FillBuffer(2);
return (ushort)((int)this.m_buffer[0] | (int)this.m_buffer[1] << 8);
}
protected virtual void FillBuffer(int numBytes)
{
if (this.m_disposed)
{
throw new ObjectDisposedException("BinaryReader", "Cannot read from a closed BinaryReader.");
}
if (this.m_stream == null)
{
throw new IOException("Stream is invalid");
}
this.CheckBuffer(numBytes);
int num;
for (int i = 0; i < numBytes; i += num)
{
num = this.m_stream.Read(this.m_buffer, i, numBytes - i);
if (num == 0)
{
throw new EndOfStreamException();
}
}
}
private void CheckBuffer(int length)
{
if (this.m_buffer.Length <= length)
{
byte[] array = new byte[length];
Buffer.BlockCopyInternal(this.m_buffer, 0, array, 0, this.m_buffer.Length);
this.m_buffer = array;
}
}
This brings the total up to 11 function calls and 23-24 if statements. BinaryReader didn’t add too much, but the overall process is super wasteful leading to the awful performance graph above.
So how can we optimize this? The goal must surely be to minimize calls to FileStream.Read. The BinaryReader class will call it every single time we want to read two bytes, so we can’t use that. It’s a shame since functions like ReadUInt16 are so useful for reading formatted data and not just blocks of bytes.
There’s nothing stopping us from writing our own BufferedBinaryReader though. The goal is to keep a buffer inside BufferedBinaryReader with the same size as the one in the FileStream. Then we can call Read just once to fill our buffer and only incur all those function calls and if statements every 2048 times we read a ushort with a 4 kilobyte buffer. For the other 2047 times we can just assume that the user knows what they’re doing and skip all the checks. After all, they’ll just get an IndexOutOfRangeExceptioninstead of the various exception types in FileStream and BinaryReader, so it’s hardly any less safe.
Lastly, we provide some functionality to control the buffer. This comes in the form of an explicit FillBufferfunction that uses the FileStream to refill its buffer and a NumBytesAvailable property to check how many bytes have been buffered and are ready for reading.
To use BufferedBinaryReader we write a very simple loop:
// Allocate an array to hold all the values
var numValues = FileSize / sizeof(ushort);
var readValues = new ushort[numValues];
// Keep reading while there's more data
while (bufferedReader.FillBuffer())
{
// Read as many values as we can from the reader's buffer
var readValsIndex = 0;
for (
var numReads = bufferedReader.NumBytesAvailable / sizeof(ushort);
numReads > 0;
--numReads
)
{
readValues[readValsIndex++] = bufferedReader.ReadUInt16();
}
}
The BufferedBinaryReader.ReadUInt16 just looks like this:
public ushort ReadUInt16()
{
var val = (ushort)((int)buffer[bufferOffset] | (int)buffer[bufferOffset+1] << 8);
bufferOffset += 2;
return val;
}
The full source code for BufferedBinaryReader is in the following test script. It’s very basic as it only has the ability to read ushort values, but feel free to port the rest of the ReadX functions from mscorlib.dll if you’d like.
Now let’s put BufferedBinaryReader to the test against BinaryReader. The following test script has the test code for that as well as the performance chart above.
using System;
using System.IO;
using UnityEngine;
public class BufferedBinaryReader : IDisposable
{
private readonly Stream stream;
private readonly byte[] buffer;
private readonly int bufferSize;
private int bufferOffset;
private int numBufferedBytes;
public BufferedBinaryReader(Stream stream, int bufferSize)
{
this.stream = stream;
this.bufferSize = bufferSize;
buffer = new byte[bufferSize];
bufferOffset = bufferSize;
}
public int NumBytesAvailable { get { return Math.Max(0, numBufferedBytes - bufferOffset); } }
public bool FillBuffer()
{
var numBytesUnread = bufferSize - bufferOffset;
var numBytesToRead = bufferSize - numBytesUnread;
bufferOffset = 0;
numBufferedBytes = numBytesUnread;
if (numBytesUnread > 0)
{
Buffer.BlockCopy(buffer, numBytesToRead, buffer, 0, numBytesUnread);
}
while (numBytesToRead > 0)
{
var numBytesRead = stream.Read(buffer, numBytesUnread, numBytesToRead);
if (numBytesRead == 0)
{
return false;
}
numBufferedBytes += numBytesRead;
numBytesToRead -= numBytesRead;
numBytesUnread += numBytesRead;
}
return true;
}
public ushort ReadUInt16()
{
var val = (ushort)((int)buffer[bufferOffset] | (int)buffer[bufferOffset+1] << 8);
bufferOffset += 2;
return val;
}
public void Dispose()
{
stream.Close();
}
}
public class TestScript : MonoBehaviour
{
private const int FileSize = 10 * 1024 * 1024;
void Start()
{
var path = Path.Combine(Application.persistentDataPath, "bigfile.dat");
try
{
File.WriteAllBytes(path, new byte[FileSize]);
TestFileStream(path);
TestBinaryReaders(path);
}
finally
{
File.Delete(path);
}
}
private void TestFileStream(string path)
{
using (var stream = new FileStream(path, FileMode.Open))
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var readBytes = new byte[FileSize];
var log = "Read Size,Time\n";
foreach (var readSize in new[]{ 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048, 4096 })
{
stream.Position = 0;
stopwatch.Reset();
stopwatch.Start();
var offset = 0;
do
{
offset += stream.Read(readBytes, offset, Math.Min(readSize, FileSize - offset));
}
while (offset < FileSize);
var time = stopwatch.ElapsedMilliseconds;
log += readSize + "," + time + "\n";
}
Debug.Log(log);
}
}
private void TestBinaryReaders(string path)
{
using (var stream = new FileStream(path, FileMode.Open))
{
var stopwatch = System.Diagnostics.Stopwatch.StartNew();
var log = "Reader,Time\n";
var numValues = FileSize / sizeof(ushort);
var readValues = new ushort[numValues];
var reader = new BinaryReader(stream);
stopwatch.Reset();
stopwatch.Start();
for (var i = 0; i < numValues; ++i)
{
readValues[i] = reader.ReadUInt16();
}
var time = stopwatch.ElapsedMilliseconds;
log += "BinaryReader," + time + "\n";
stream.Position = 0;
var bufferedReader = new BufferedBinaryReader(stream, 4096);
stopwatch.Reset();
stopwatch.Start();
while (bufferedReader.FillBuffer())
{
var readValsIndex = 0;
for (
var numReads = bufferedReader.NumBytesAvailable / sizeof(ushort);
numReads > 0;
--numReads
)
{
readValues[readValsIndex++] = bufferedReader.ReadUInt16();
}
}
time = stopwatch.ElapsedMilliseconds;
log += "BufferedBinaryReader," + time + "\n";
Debug.Log(log);
}
}
}
If you want to try out the test yourself, simply paste the above code into a TestScript.cs file in your Unity project’s Assets directory and attach it to the main camera game object in a new, empty project. Then build in non-development mode for 64-bit processors and run it windowed at 640×480 with fastest graphics. I ran it that way on this machine:
- 2.3 Ghz Intel Core i7-3615QM
- Mac OS X 10.11.5
- Apple SSD SM256E, HFS+ format
- Unity 5.4.0f3, Mac OS X Standalone, x86_64, non-development
- 640×480, Fastest, Windowed
And here are the results I got:
| Reader | Time |
|---|---|
| BinaryReader | 272 |
| BufferedBinaryReader | 24 |
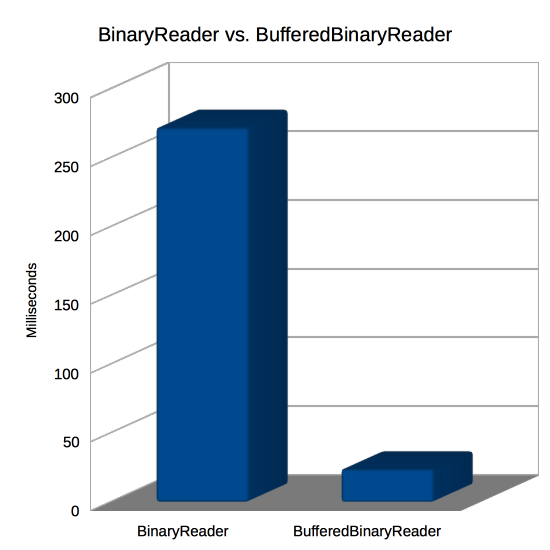
This shows that BufferedBinaryReader is about 11x faster than regular BinaryReader! That shouldn’t be much of a surprise since the performance test above showed similar times for 2 byte reads (272 here, 227 there) versus 4096 byte reads (24 here, 3 there). Remember the discussion of spreading the file loading out over multiple frames and maybe reading it from another thread? At only 24 milliseconds for a 10 megabyte file, that’s probably not going to be necessary if you have a more reasonable file size like 1 megabyte. Your code can be a lot simpler and the user can have their data immediately!
In conclusion, FileStream has a lot of CPU overhead for every call to its Read function regardless of the internal buffering its doing for calls to the OS’ native read function. To speed up your reads from disk, read as much as you can into your own buffer to minimize the FileStream overhead. A class like BufferedBinaryReader can make this pretty painless and massively speed up your performance.
If you’ve got any questions or tips you’d like to share about file I/O performance in Unity, please drop me a line in the comments!
#1 by Simon on September 5th, 2016 · | Quote
What would be interesting is how File.ReadAllBytes() performs in comparison to this. In many scenarios it would be ok to keep all bytes in memory until the file is fully processed I guess
#2 by jackson on September 5th, 2016 · | Quote
Here’s what
File.ReadAllByteslooks like when decompiled:public static byte[] ReadAllBytes(string path) { byte[] result; using (FileStream fileStream = File.OpenRead(path)) { long length = fileStream.Length; if (length > 2147483647L) { throw new IOException("Reading more than 2GB with this call is not supported"); } int num = 0; int i = (int)length; byte[] array = new byte[length]; while (i > 0) { int num2 = fileStream.Read(array, num, i); if (num2 == 0) { throw new IOException("Unexpected end of stream"); } num += num2; i -= num2; } result = array; } return result; }Since the read size (
i) is always the whole remaining file, it’s almost always going to be really large. I did a quick test using the same computer as in the article and it performs about as well as the 4096 byte read size.The downside, of course, is that you still have to deal with a raw byte array rather than formatted values like
ushort. You could wrap that byte array in aMemoryStreamand aBinaryReader, but you’ll suffer similar problems with those as described in the article. I took a quick look atMemoryStream.Readand it costs 12ifs, 2 C# function calls, and 2 native function calls. Cheaper thanFileStream.Read, but still really expensive!